Wikipedia Clickstream - Getting Started
This post gives an introduction to working with the new February release of the Wikipedia Clickstream dataset. The data shows how people get to a Wikipedia article and what articles they click on next. In other words, it gives a weighted network of articles, where each edge weight corresponds to how often people navigate from one page to another. To give an example, consider the figure below, which shows incoming and outgoing traffic to the “London” article.
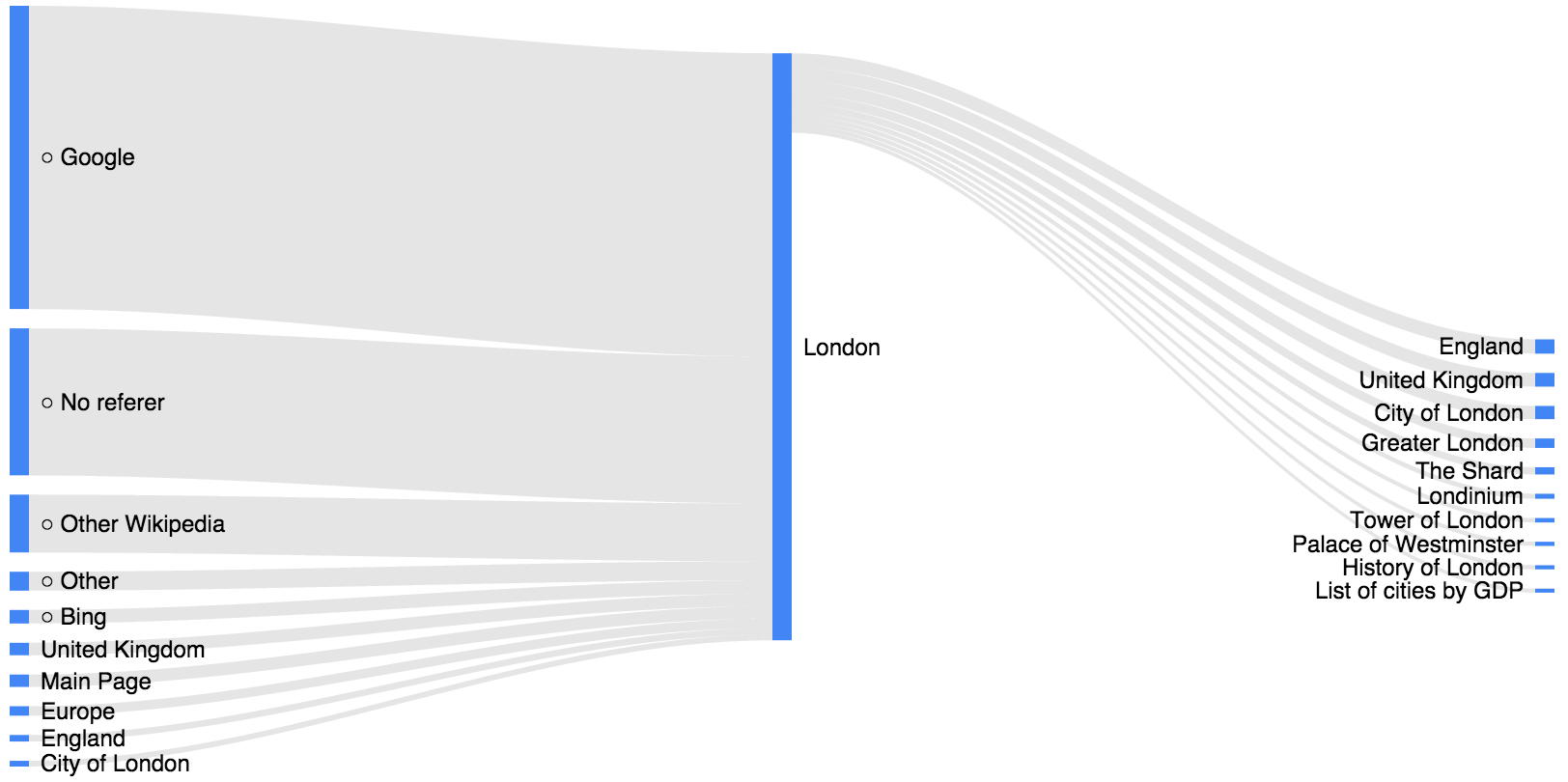
The example shows that most people found the “London” page through Google Search and that only a small fraction of readers went on to another article. Before diving into some examples of working with the data, let me give a more detailed explanation of how the data was collected.
Data Preparation
The data contains counts of (referer, resource) pairs extracted from the request logs of English Wikipedia. When a client requests a resource by following a link or performing a search, the URI of the webpage that linked to the resource is included with the request in an HTTP header called the “referer”. This data captures 22 million (referer, resource) pairs from a total of 3.2 billion requests collected during the month of February 2015.
The dataset only includes requests for articles in the main namespace of the desktop version of English Wikipedia.
Referers were mapped to a fixed set of values corresponding to internal traffic or external traffic from one of the top 5 global traffic sources to English Wikipedia, based on this scheme:
- an article in the main namespace of English Wikipedia -> the article title
- any Wikipedia page that is not in the main namespace of English Wikipedia -> other-wikipedia
- an empty referer -> other-empty
- a page from any other Wikimedia project -> other-internal
- Google -> other-google
- Yahoo -> other-yahoo
- Bing -> other-bing
- Facebook -> other-facebook
- Twitter -> other-twitter
- anything else -> other-other
MediaWiki Redirects are used to forward clients from one page name to another. They can be useful if a particular article is referred to by multiple names, or has alternative punctuation, capitalization or spellings. Requests for pages that get redirected were mapped to the page they redirect to. For example, requests for ‘Obama’ redirect to the ‘Barack_Obama’ page. Redirects were resolved using a snapshot of the production redirects table from February 28 2015.
Redlinks are links to an article that does not exist. Either the article was deleted after the creation of the link or the author intended to signal the need for such an article. Requests for redlinks are included in the data.
We attempt to exclude spider traffic by classifying user agents with the ua- parser library and a few additonal Wikipedia specific filters. Furthermore, we attempt to filter out traffic from bots that request a page and then request all or most of the links on that page (BFS traversal) by setting a threshold on the rate at which a client can request articles with the same referer. Requests that were made at too high of a rate get discarded. For the exact details, see here and here. The threshold is quite high to avoid excluding human readers who open tabs as they read. As a result, requests from slow moving bots are likely to remain in the data. More sophisticated bot detection that evaluates the clients entire set of requests is an avenue of future work.
Finally, any (referer, resource) pair with 10 or fewer observations was removed from the dataset.
Format
The data includes the following 6 fields:
- prev_id: if the referer does not correspond to an article in the main namespace of English Wikipedia, this value will be empty. Otherwise, it contains the unique MediaWiki page ID of the article corresponding to the referer i.e. the previous article the client was on
- curr_id: the unique MediaWiki page ID of the article the client requested
- n: the number of occurrences of the (referer, resource) pair
- prev_title: the result of mapping the referer URL to the fixed set of values described above
- curr_title: the title of the article the client requested
- type
- “link” if the referer and request are both articles and the referer links to the request
- “redlink” if the referer is an article and links to the request, but the request is not in the produiction enwiki.page table
- “other” if the referer and request are both articles but the referer does not link to the request. This can happen when clients search or spoof their refer
Getting to know the Data
There are various quirks in the data due to the dynamic nature of the network of articles in English Wikipedia and the prevalence of requests from automata. The following section gives a brief overview of the data fields and caveats that need to be kept in mind.
Loading the Data
First let’s load the data into a pandas DataFrame.
import pandas as pd
df = pd.read_csv("2015_02_clickstream.tsv", sep='\t', header=0)
#we won't use ids here, so lets discard them
df = df[['prev_title', 'curr_title', 'n', 'type']]
df.columns = ['prev', 'curr', 'n', 'type']
Top articles
It has been possible for the public to estimate which pages get the most pageviews per month from the public pageview dumps that WMF releases. Unfortunately, there is no attempt to remove spiders and bots from those dumps. This month the “Layer 2 Tunneling Protocol” was the 3rd most requested article. The logs show that this article was requested by a small number of clients hundreds of times per minute within a 4 day window. This kind of request pattern is removed from the clickstream data, which gives the following as the top 10 pages:
df.groupby('curr').sum().sort('n', ascending=False)[:10]
| Main_Page | 127500620 |
| 87th_Academy_Awards | 2559794 |
| Fifty_Shades_of_Grey | 2326175 |
| Alive | 2244781 |
| Chris_Kyle | 1709341 |
| Fifty_Shades_of_Grey_(film) | 1683892 |
| Deaths_in_2015 | 1614577 |
| Birdman_(film) | 1545842 |
| Islamic_State_of_Iraq_and_the_Levant | 1406530 |
| Stephen_Hawking | 1384193 |
The most requested pages tend to be about media that was popular in February. The exceptions are the “Deaths_in_2015” article and the “Alive” disambiguation article. The “Main_Page” links to “Deaths_in_2015” and is the top referer to this article, which would explain the high number of requests. The fact that the “Alive” disambiguation page gets so many hits seems suspect and is likely to be a fruitful case to investigate to improve the bot filtering.
Top Referers
The clickstream data aslo let’s us investigate who the top referers to Wikipedia are:
df.groupby('prev').sum().sort('n', ascending=False)[:10]
| other-google | 1494662520 |
| other-empty | 347424627 |
| other-wikipedia | 129619543 |
| other-other | 77496915 |
| other-bing | 65895496 |
| other-yahoo | 48445941 |
| Main_Page | 29897807 |
| other-twitter | 19222486 |
| other-facebook | 2312328 |
| 87th_Academy_Awards | 1680559 |
The top referer by a large margin is Google. Next comes refererless traffic (usually clients using HTTPS). Then come other language Wikipedias and pages in English Wikipedia that are not in the main (i.e. article) namespace. Bing directs significantly more traffic to Wikipedia than Yahoo. Social media referals are tiny compared to Google, with twitter leading 10x more requests to Wikipedia than Facebook.
Trending on Social Media
Lets look at what articles were trending on Twitter:
df_twitter = df[df['prev'] == 'other-twitter']
df_twitter.groupby('curr').sum().sort('n', ascending=False)[:5]
| Johnny_Knoxville | 198908 |
| Peter_Woodcock | 126259 |
| 2002_Tampa_plane_crash | 119906 |
| Sơn_Đoòng_Cave | 116012 |
| The_boy_Jones | 114401 |
I have no explanations for this, but if you find any of the tweets linking to these articles, I would be curious to see why they got so many click-throughs.
Most Requested Missing Pages
Next let’s look at the most popular redinks. Redlinks are links to a Wikipedia page that does not exist, either because it has been deleted, or because the author is anticipating the creation of the page. Seeing which redlinks are the most viewed is interesting because it gives some indication about demand for missing content. Since the set of pages and links is constantly changing, the labeling of redlinks is not an exact science. In this case, I used a static snapshot of the page and pagelinks production tables from Feb 28th to mark a page as a redlink.
df_redlinks = df[df['type'] == 'redlink']
df_redlinks.groupby('curr').sum().sort('n', ascending=False)[:5]
| 2027_Cricket_World_Cup | 6782 |
| Rethinking | 5279 |
| Chris_Soules | 5229 |
| Anna_Lezhneva | 3764 |
| Jillie_Mack | 3685 |
Searching Within Wikipedia
Usually, clients navigate from one article to another through following a link.
The other prominent case is search. The article from which the user searched is
also passed as the referer to the found article. Hence, you will find a high
count of (Wikipedia, Chris_Kyle) tuples. People went to the “Wikipedia”
article to search for “Chris_Kyle”. There is not a link to the “Chris_Kyle”
article from the “Wikipedia” article. Finally, it is possible that the client
messed with their referer header. The vast majority of requests with an internal
referer correspond to a true link.
df_search = df[df['type'] == 'other']
df_search = df_search[df_search.prev.str.match("^other.*").apply(bool) == False]
print "Number of searches/ incorrect referers: %d" % df_search.n.sum()
Number of searches/ incorrect referers: 106772349
df_link = df[df['type'] == 'link']
df_link = df_link[df_link.prev.str.match("^other.*").apply(bool) == False]
print "Number of links followed: %d" % df_link.n.sum()
Number of links followed: 983436029
Inflow vs Outflow
You might be tempted to think that there can’t be more traffic coming out of a node (ie. article) than going into a node. This is not true for two reasons. People will follow links in multiple tabs as they read an article. Hence, a single pageview can lead to multiple records with that page as the referer. The data is also certain to include requests from bots which we did not correctly filter out. Bots will often follow most, if not all, the links in the article. Lets look at the ratio of incoming to outgoing links for the most requested pages.
df_in = df.groupby('curr').sum() # pageviews per article
df_in.columns = ['in_count',]
df_out = df.groupby('prev').sum() # link clicks per article
df_out.columns = ['out_count',]
df_in_out = df_in.join(df_out)
df_in_out['ratio'] = df_in_out['out_count']/df_in_out['in_count'] #compute ratio if outflow/infow
df_in_out.sort('in_count', ascending = False)[:3]
| curr | in_count | out_count | ratio |
| Main_Page | 127500620 | 29897807 | 0.234491 |
| 87th_Academy_Awards | 2559794 | 1680559 | 0.656521 |
| Fifty_Shades_of_Grey | 2326175 | 1146354 | 0.492806 |
Looking at the pages with the highest ratio of outgoing to incoming traffic reveals how messy the data is, even after the careful data preparation described above.
df_in_out.sort('ratio', ascending = False)[:3]
| curr | in_count | out_count | ratio |
|---|---|---|---|
| List_of_Major_League_Baseball_players_(H) | 57 | 1323 | 23.210526 |
| 2001–02_Slovak_Superliga | 22 | 472 | 21.454545 |
| Principle_of_good_enough | 23 | 374 | 16.260870 |
All of these pages have more traversals of a single link than they have requests for the page to begin with. As a post processing step, we might enforce that there can’t be more traversals of a link than there were requests to the page. Better bot filtering should help reduce this issue in the future.
df_post = pd.merge(df, df_in, how='left', left_on='prev', right_index=True)
df_post['n'] = df_post[['n', 'in_count']].min(axis=1)
del df_post['in_count']
Network Analysis
We can think of Wikipedia as a network with articles as nodes and links between articles as edges. This network has been available for analysis via the production pagelinks table. But what does it mean if there is a link between articles that never gets traversed? What is it about the pages that send their readers to other pages with high probability? What makes a link enticing to follow? What are the cliques of articles that send lots of traffic to each other? These are just some of the questions, this data set allows us to investigate. I’m sure you will come up with many more.
Getting the Data
The dataset is released under CC0. The canonical citation and most up-to-date version of the data can be found at:
Ellery Wulczyn, Dario Taraborelli (2015). Wikipedia Clickstream. figshare. doi:10.6084/m9.figshare.1305770
An IPython Notebook version of this post can be found here.